Book Summary: Site Reliability Engineering, Part 1, How a service would be deployed at Google scale

How to deploy an application so that it works well at large scale? Of course there is no easy answer for such a question. It probably would take an entire book to explain that. Fortunately, in Site Reliability Engineering book, Google explained briefly what it might be like.
They explained how to deploy sample service in the Google production environment. This will give us more insights on how complex it might get if we would deploy a simple service to serve millions of users around the world.
Suppose we want to offer a service that lets you determine where a given word is used throughout all of Shakespeare’s works. It's a typical search problem which means that it can be divided into two components:
- Indexing and writing the index into a Bigtable. This can be run once or frequently based on the problem (in Shakespeare’s case, it's enough to run it once). This can be implemented using MapReduce (scroll down for a simpler example of MapReduce task) which will split Shakespeare’s work (text) into hundreds of parts, assign each part to a worker, all workers should run in parallel then they will send the results to a reducer task which will create a tuple of (word, list of locations) and write it to a row in a Bigtable, using the word as the key.
- A frontend application for users to be able to search for words and see the results.
Here is how a user request will be served:
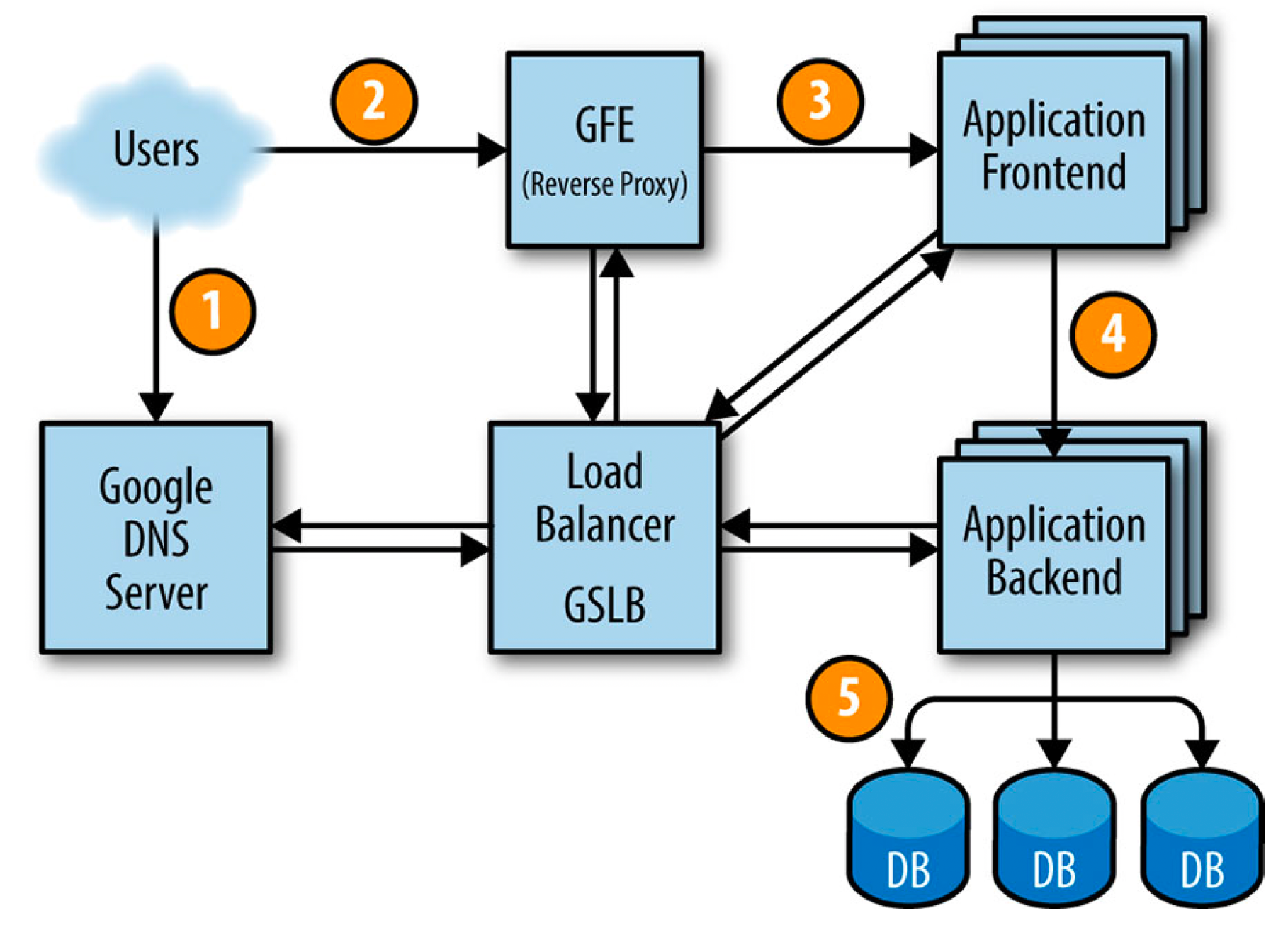
First, the user goes to shakespeare.google.com to obtain the corresponding IP address from Google’s DNS server, which talks to GSLB to pick which server IP address to send to this user. The browser connects to the HTTP server on this IP. This server (named the Google Frontend, or GFE) is a reverse proxy that terminates the TCP connection (2).
The GFE looks up which service is required (web search, maps, or—in this case—Shakespeare). Again using GSLB, the server finds an available Shakespeare frontend server, and sends that server an RPC containing the HTTP request (3).
The Shakespeare frontend server now needs to contact the Shakespeare backend server: The frontend server contacts GSLB to obtain the BNS address of a suitable and unloaded backend server (4).
That Shakespeare backend server now contacts a Bigtable server to obtain the requested data (5).
The answer is returned to the Shakespeare backend server. The backend hands the results to the Shakespeare frontend server, which assembles the HTML and returns the answer to the user.
This entire chain of events is executed in the blink of an eye—just a few hundred milliseconds! Because many moving parts are involved, there are many potential points of failure; in particular, a failing GSLB would break the entire application. How can we protect our application from single point of failure and make it more reliable? That's what will be covered in the next section.
Ensuring Reliability
Let's assume we did load testing for our infrastructure and found that one backend server can handle about 100 queries per second (QPS). Let’s also assume that it's expected to get about 3500 QPS as a peak load, so we need at least 35 replicas of the backend server. But actually we need 37 tasks in the job, or N+2 because:
- During updates, one task at a time will be unavailable, leaving 36 tasks.
- A machine failure might occur during a task update, leaving only 35 tasks, just enough to serve peak load.
A closer examination of user traffic shows our peak usage is distributed globally:
- 1,430 QPS from North America,
- 290 QPS from South America,
- 1,400 QPS from Europe and Africa,
- 350 QPS from Asia and Australia.
Instead of locating all backends at one site, we distribute them across the USA, South America, Europe, and Asia. Allowing for N+2 redundancy per region means that we end up with
- 17 tasks in the USA,
- 16 in Europe,
- 6 in Asia,
- 5 in South America
However, we decided to use 4 tasks (instead of 5) in South America, to lower the overhead of N+2 to N+1. In this case, we’re willing to tolerate a small risk of higher latency in exchange for lower hardware costs. If GSLB redirects traffic from one continent to another when our South American datacenter is over loaded, we can save 20% of the resources we’d spend on hardware. In the larger regions, we’ll spread tasks across two or three clusters for extra resiliency.
Because the backends need to contact the Bigtable holding the data, we need to also design this storage element strategically. A backend in Asia contacting a Bigtable in the USA adds a significant amount of latency, so we replicate the Bigtable in each region. Bigtable replication helps us in two ways:
- It provides resilience when a Bigtable server fail
- It lowers data-access latency.
Conclusion
This was just a quick introduction about how it would be like to design a reliable system. Of course the reality is much more complicated than this. Next we will take a deeper look at some SRE terminologies and how to implement them in our organisations.
An simpler example of MapReduce
This is a very simple example of MapReduce. No matter the amount of data you need to analyze, the key principles remain the same.
Assume you have ten CSV files with three columns (date, city, temperature). We want to find the maximum temperature for each city across the data files (note that each file might have the same city represented multiple times).
Using the MapReduce framework, we can break this down into ten map tasks, where each mapper works on one of the files. The mapper task goes through the data and returns the maximum temperature for each city.
For example, (Cairo, 45) (Berlin, 32) (Porto, 33) (Rome, 36)
After all map tasks are done, the output streams would be fed into the reduce tasks, which combine the input results and output a single value for each city, producing a final result.
For example, (Cairo, 46) (Berlin, 32) (Porto, 38) (Rome, 36), Barcelona (40), ..
