Book Summary: Site Reliability Engineering, Part 2, Error Budgets and Service Level Objectives (SLOs)

It would be nice to build 100% reliable services. Ones that never fail. right? absolutely not. It's going to be really bad to do such a thing because it's very expensive and it will limit how fast new features can be developed and delivered to the users. Also users typically won’t notice the difference between high reliability and extreme reliability in a service, because the user experience is dominated by less reliable components like the cellular network or the device they are working with. With this in mind, rather than simply maximizing uptime, Site Reliability Engineering seeks to balance the risk of unavailability with the goals of rapid innovation and efficient service operations, so that users’ overall happiness—with features, service, and performance—is optimized.
Here is how we measure availability for a service:
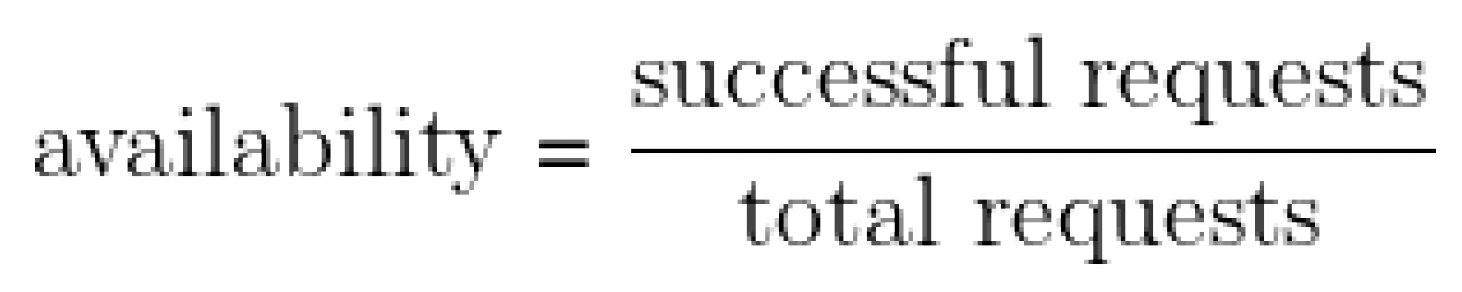
For example, a system that serves 2.5M requests in a day with a daily availability target of 99.99% can serve up to 250 errors and still hit its target for that given day.
Why Error Budgets
There is always tension between product development teams and SRE teams, given that they are generally evaluated on different metrics. Product development performance is largely evaluated on product velocity, which creates an incentive to push new code as quickly as possible. Meanwhile, SRE performance is evaluated based upon reliability of a service, which implies an incentive to push back against a high rate of change.
For example, Let's say we want to define the push frequency for a service, given that every push is risky then SRE will push for fewer deployments. On the other side, the product development team will push for more deployment because they want their work to reach the users.
Our goal here is to define an objective metric, agreed upon by both sides, that can be used to guide the negotiations in a reproducible way. The more data-based the decision can be, the better.
How to define Your Error Budget?
In order to base these decisions on objective data, the two teams jointly define a quarterly error budget based on the service’s service level objective, or SLO. The error budget provides a clear, objective metric that determines how unreliable the service is allowed to be within a single quarter. This metric removes the politics from negotiations between the SREs and the product developers when deciding how much risk to allow.
Our practice is then as follows:
- Product Management defines an SLO, which sets an expectation of how much uptime the service should have per quarter.
- The actual uptime is measured by our monitoring/observability system.
- The difference between these two numbers is the ”budget” of how much ”unreliability” is remaining for the quarter.
- As long as the uptime measured is above the SLO—in other words, as long as there is error budget remaining—new releases can be pushed.
For example, imagine that a service’s SLO is to successfully serve 99.999% of all queries per quarter. This means that the service’s error budget is a failure rate of 0.001% for a given quarter. If a problem causes us to fail 0.0002% of the expected queries for the quarter, the problem spends 20% of the service’s quarterly error budget.
The Benefits of Error Budgets
The main benefit of an error budget is that it provides a common incentive that allows both product development and SRE to focus on finding the right balance between innovation and reliability.
Many products use this control loop to manage release velocity: as long as the system’s SLOs are met, releases can continue. If SLO violations occur frequently enough to expend the error budget, releases are temporarily halted while additional resources are invested in system testing and development to make the system more resilient, improve its performance, and so on. More subtle and effective approaches are available than this simple on/off technique, for instance, slowing down releases or rolling them back when the SLO-violation error budget is close to being used up.
For example, if product development wants to skimp on testing or increase push velocity and SRE is resistant, the error budget guides the decision. When the budget is large, the product developers can take more risks. When the budget is nearly drained, the product developers themselves will push for more testing or slower push velocity, as they don’t want to risk using up the budget and stall their launch. In effect, the product development team becomes self-policing. They know the budget and can manage their own risk. (Of course, this outcome relies on an SRE team having the authority to actually stop launches if the SLO is broken.)
What happens if a network outage or datacenter failure reduces the measured SLO? Such events also eat into the error budget. As a result, the number of new pushes may be reduced for the remainder of the quarter. The entire team supports this reduction because everyone shares the responsibility for uptime.
The budget also helps to highlight some of the costs of overly high reliability targets, in terms of both inflexibility and slow innovation. If the team is having trouble launching new features, they may elect to loosen the SLO (thus increasing the error budget) in order to increase innovation.
Conclusion
- Managing service reliability is largely about managing risk, and managing risk can be costly.
- 100% is probably never the right reliability target: not only is it impossible to achieve, it’s typically more reliability than a service’s users want or notice. Match the profile of the service to the risk the business is willing to take.
- An error budget aligns incentives and emphasizes joint ownership between SRE and product development. Error budgets make it easier to decide the rate of releases and to effectively defuse discussions about outages with stakeholders, and allows multiple teams to reach the same conclusion about production risk without problems.
